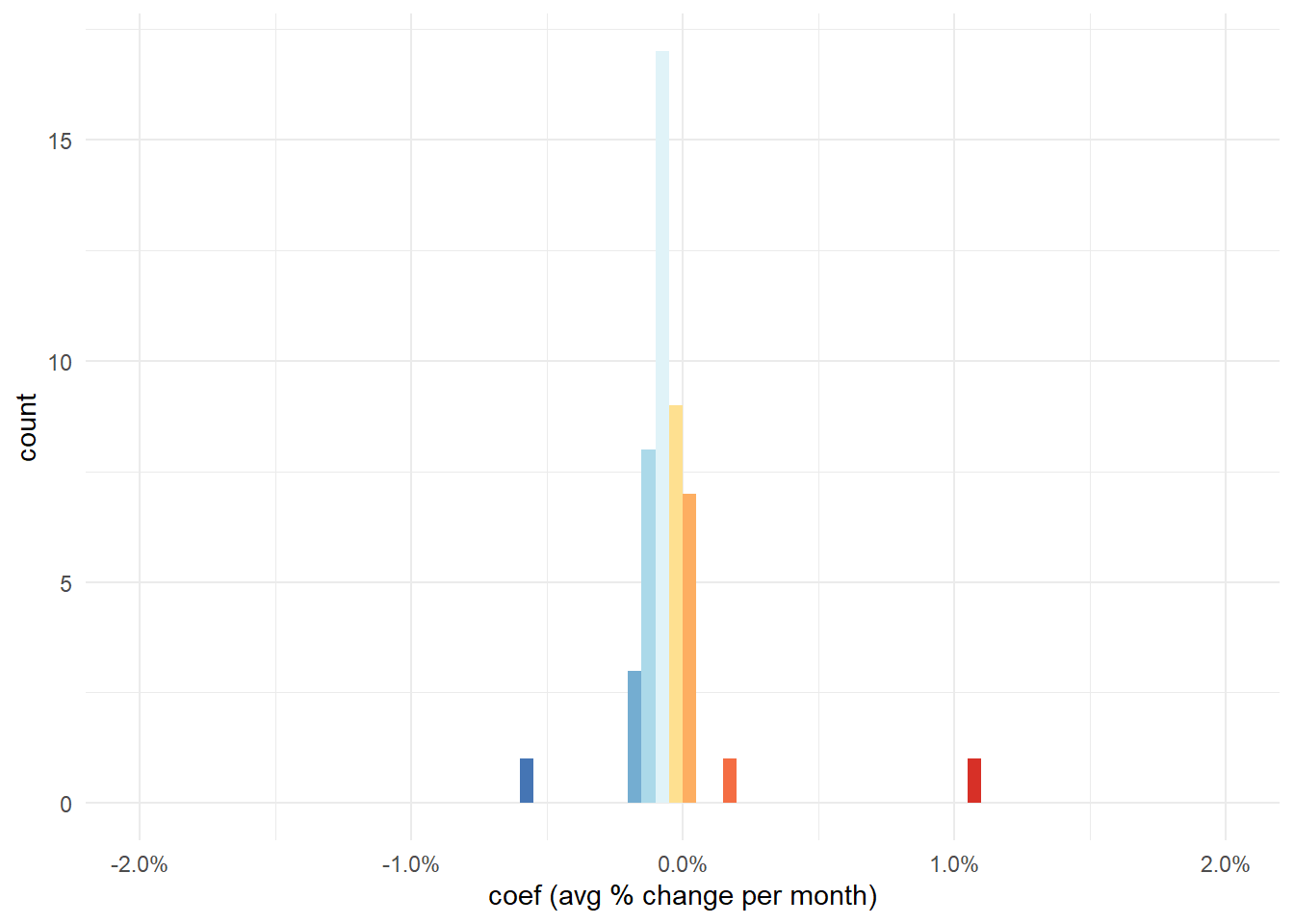── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Warning in readLines(con): incomplete final line found on
'https://openprescribing.net/api/1.0/org_location/?org_type=ccg'
GP surgeries
Approximate locations of all registered GP surgeries can be obtained. For example, for Bradford (ICB code: 36J)
bradford_code <-"36J"
Reading the built-up areas data
builtup_bounds <-st_read("OS Open Built Up Areas.gpkg",layer ="os_open_built_up_areas")
Reading layer `os_open_built_up_areas' from data source
`C:\Users\ts18jpf\OneDrive - University of Leeds\03_PhD\00_Misc_projects\Eng-Presc-Data\OS Open Built Up Areas.gpkg'
using driver `GPKG'
Simple feature collection with 8585 features and 7 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 65300 ymin: 10000 xmax: 655625 ymax: 1177650
Projected CRS: OSGB36 / British National Grid
Selecting the biggest builtup area within the NHS region
Why it matters: Why Asthma Still Kills reports that high use of short acting beta agonists (salbutamol and terbutaline) and poor adherence to inhaled corticosteroids in asthma suggests poor control - these patients should be reviewed regularly to ensure good control.
The NHS England National Medicines Optimisation Opportunities for 2023/24 identify improving patient outcomes from the use of inhalers as an area for improvement.
Description: Prescribing of short acting beta agonist (SABA) inhalers - salbutamol and terbutaline - compared with prescribing of inhaled corticosteroid inhalers and SABA inhalers
saba <-read_csv(paste0("https://openprescribing.net/api/1.0/measure_by_practice/?format=csv&org=", bradford_code,"&parent_org_type=ccg&measure=saba"))
Rows: 5368 Columns: 9
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (4): measure, org_type, org_id, org_name
dbl (4): numerator, denominator, calc_value, percentile
date (1): date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.
Exploring the data
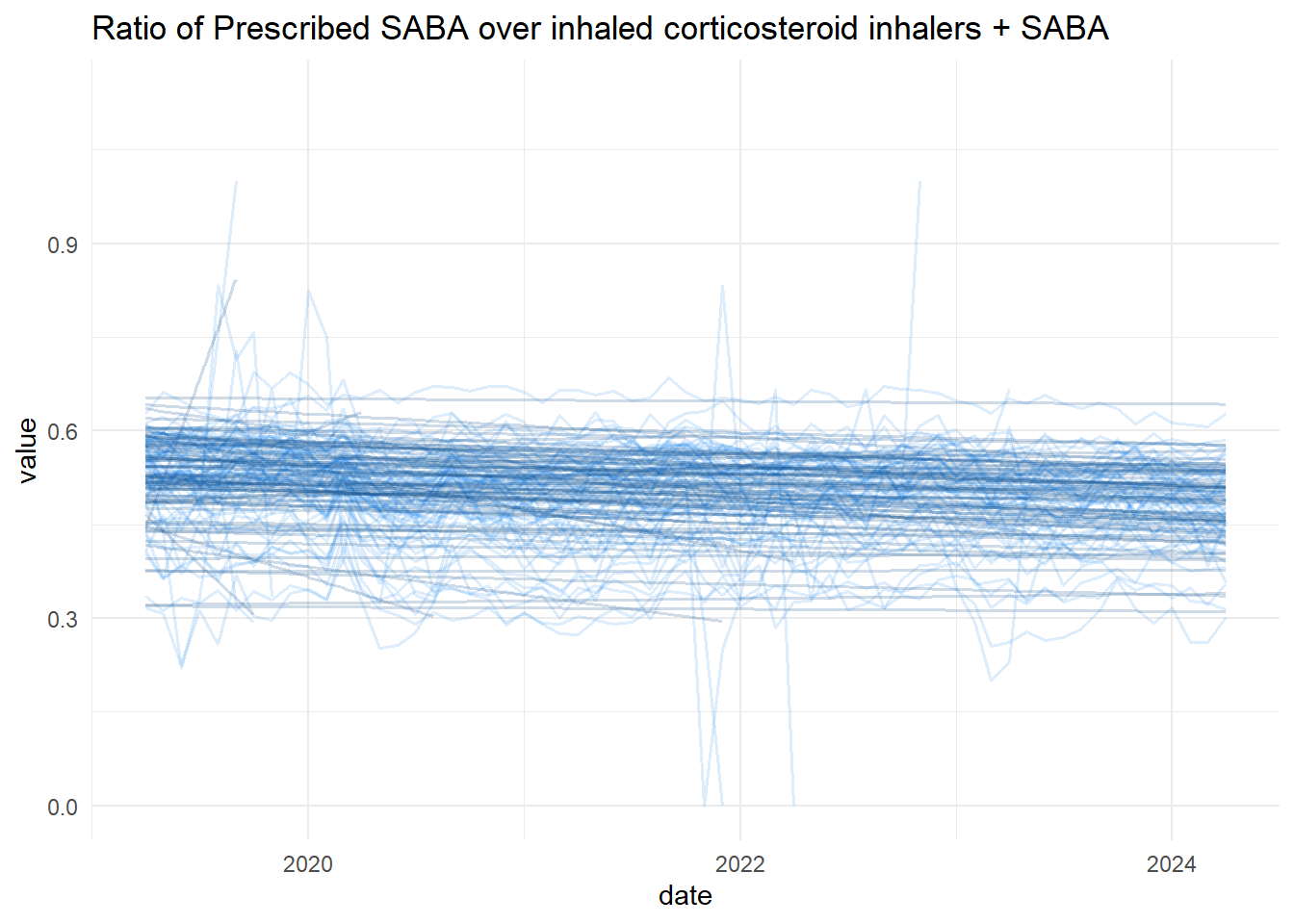
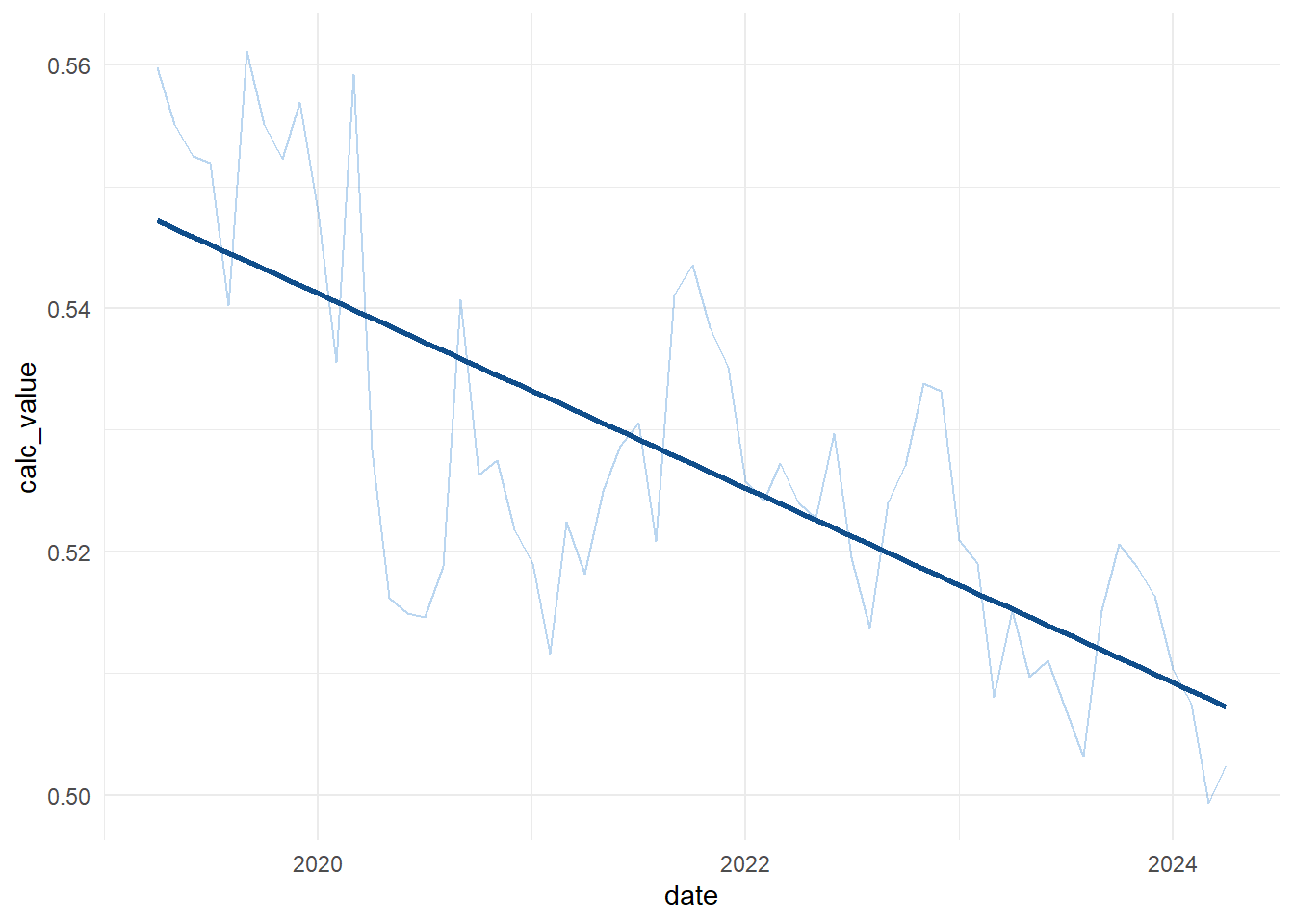
It is possible to extract the trends of both metrics. Below a graphical extract of one of the metrics for Bradford.
head(saba)
# A tibble: 6 × 9
measure org_type org_id org_name date numerator denominator calc_value
<chr> <chr> <chr> <chr> <date> <dbl> <dbl> <dbl>
1 saba practice B83021 FARFIELD … 2020-01-01 896 1605 0.558
2 saba practice B82020 CROSS HIL… 2020-01-01 679 1315 0.516
3 saba practice B82028 FISHER ME… 2020-01-01 537 1392 0.386
4 saba practice B82053 DYNELEY H… 2020-01-01 393 930 0.423
5 saba practice B82099 GRASSINGT… 2020-01-01 0 0 NA
6 saba practice B83002 ILKLEY & … 2020-01-01 115 275 0.418
# ℹ 1 more variable: percentile <dbl>
saba |>ggplot(aes(x = date,y = calc_value,groups = org_id))+geom_line(alpha =0.15, col ="dodgerblue2",linewidth =0.65)+stat_smooth(geom ="line",method ="lm",alpha =0.2, col ="dodgerblue4",linewidth =0.7)+theme_minimal()+labs(title ="Ratio of Prescribed SABA over inhaled corticosteroid inhalers + SABA",y ="value" )
`geom_smooth()` using formula = 'y ~ x'
Warning: Removed 1423 rows containing non-finite outside the scale range
(`stat_smooth()`).
Warning: Removed 1417 rows containing missing values or values outside the scale range
(`geom_line()`).
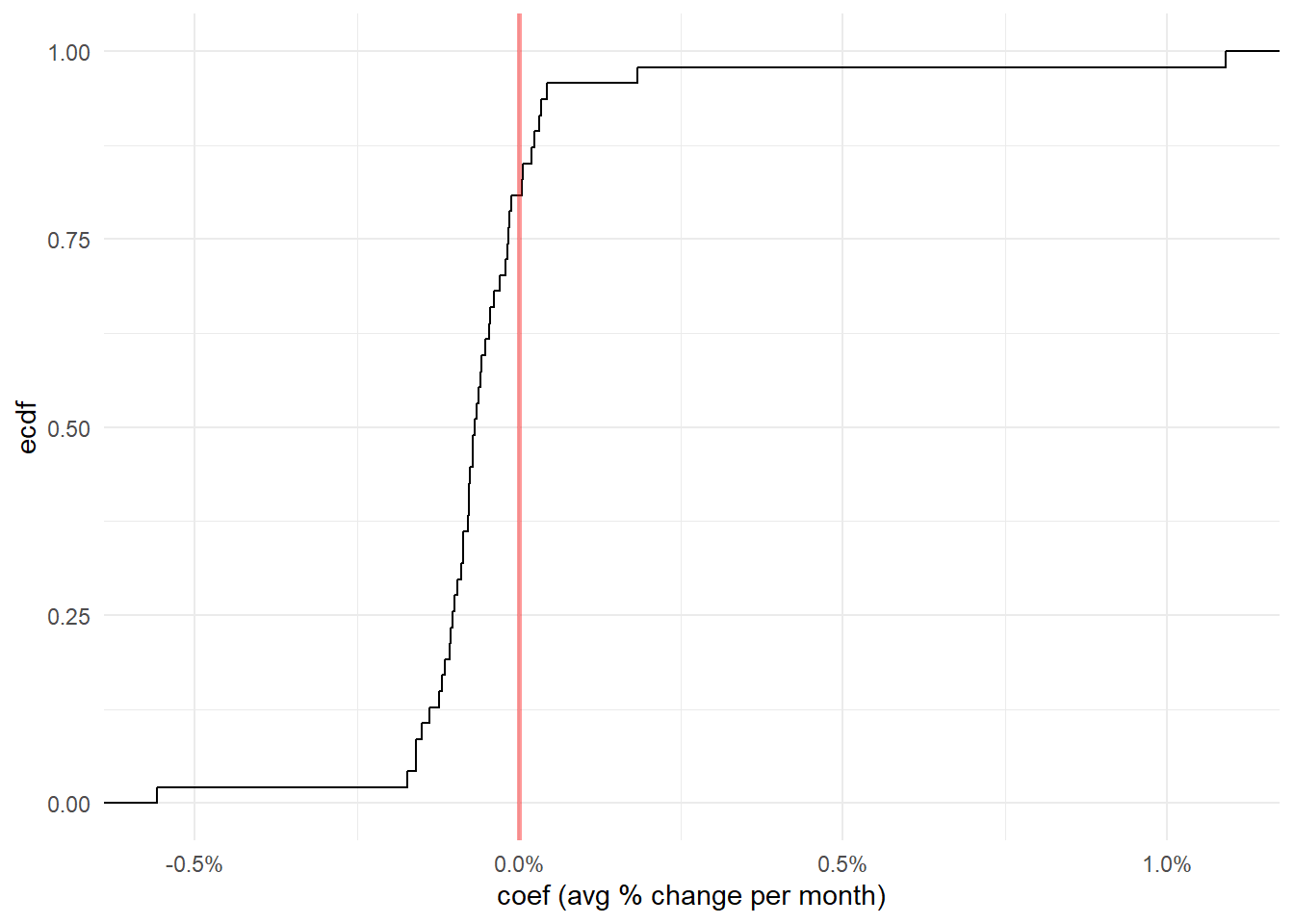
Calculating an overall trend
First let’s check the data quality for all practices and remove the NAs.
saba |>drop_na() |>summarise(n_reports =n(),.by = org_id) |>arrange(n_reports)
[v3->v4] `tm_dots()`: instead of `style = "fisher"`, use fill.scale =
`tm_scale_intervals()`.
ℹ Migrate the argument(s) 'style', 'midpoint', 'palette' (rename to 'values')
to 'tm_scale_intervals(<HERE>)'
For small multiples, specify a 'tm_scale_' for each multiple, and put them in a
list: 'fill'.scale = list(<scale1>, <scale2>, ...)'
[v3->v4] `tm_dots()`: use 'fill' for the fill color of polygons/symbols
(instead of 'col'), and 'col' for the outlines (instead of 'border.col').
[cols4all] color palettes: use palettes from the R package cols4all. Run
`cols4all::c4a_gui()` to explore them. The old palette name "Spectral" is named
"brewer.spectral"
Multiple palettes called "spectral" found: "brewer.spectral", "matplotlib.spectral". The first one, "brewer.spectral", is returned.